A hibrid ajánlórendszerek ötvözik a kollaboratív szűrés és a tartalomalapu módszerek erősségeit, miközben csökkentik az egyes megközelítések korlátait. A hibrid architektúrák az iparági ajánlórendszerek nagy részét alkotják, mivel a valós adatokból megfigyelhető, hogy egyetlen módszer ritkán nyújt optimális teljesítményt minden szituációban.
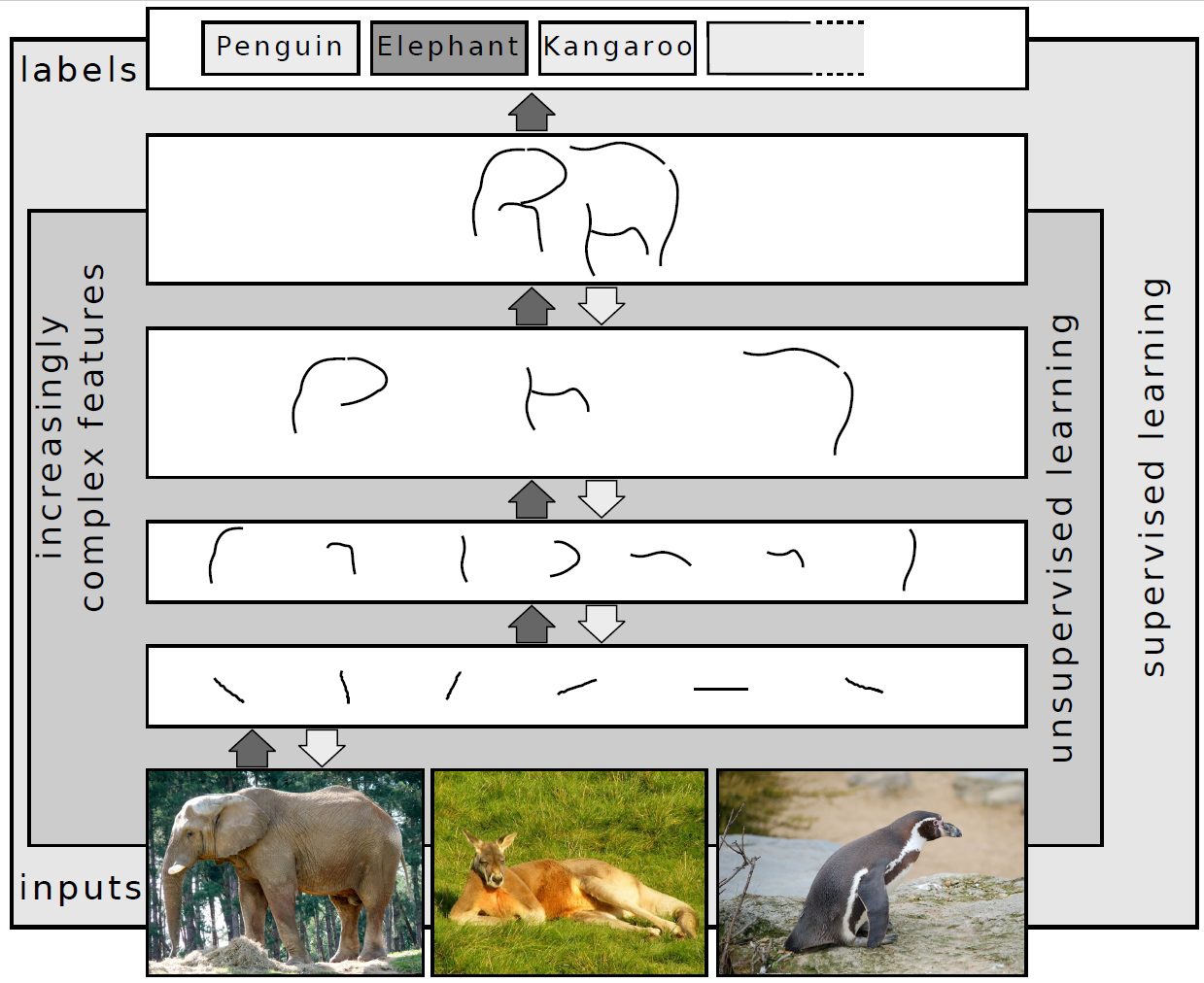
A mély tanulás lehetővé teszi a kollaboratív és tartalomalapu jelzések egyidejű feldolgozását. Forrás: Wikimedia Commons, CC BY-SA 4.0.
A hibridizáció fő stratégiái
Súlyozásos kombináció (weighted hybridization)
A legegyszerűbb megközelítésben mindkét modell ajánlási pontszámait lineárisan kombinálják egy tanult vagy kézzel beállított súlyozással. Ha a kollaboratív modell a pontszámot S_CF-ként, a tartalomalapu modell S_CB-ként adja meg, a végső pontszám: S = α·S_CF + (1-α)·S_CB. Az α paraméter meghatározható tanítóadatokon keresztül vagy domain-specifikus tapasztalat alapján.
Kaskád megközelítés (cascade hybridization)
A kaszkád struktúrában az egyik modell durva szűrést végez (pl. 100 jelöltelemet jelöl ki), majd a második modell finomabb rangsorolást hajt végre ezen a szűkített halmazon. A Google és a YouTube publikált dokumentumai (Covington et al., 2016 RecSys előadás) leírják, hogy a YouTube-on is kétlépéses visszakeresési és rangsorolási folyamat működik.
Váltásos megközelítés (switching hybridization)
Bizonyos feltételek teljesülésekor a rendszer egyik vagy másik módszert aktiválja. Például: ha az új felhasználóról nincs elegendő interakciós adat (hidegindítási helyzet), a tartalomalapu modell veszi át az ajánlás elvégzését. Ha az interakciók száma elér egy küszöbértéket, a rendszer a kollaboratív szűrőre vált.
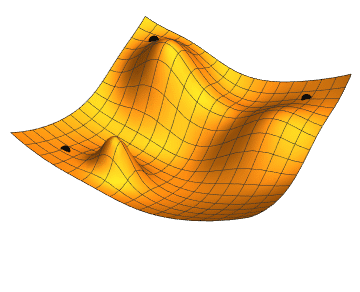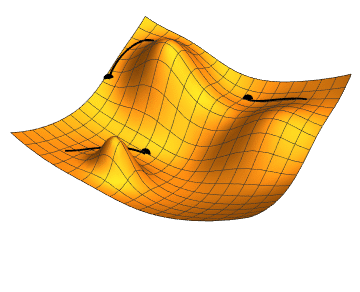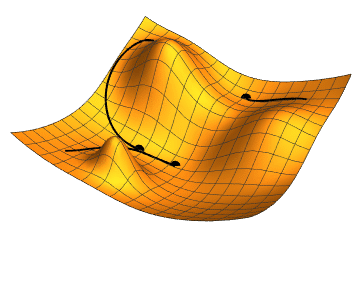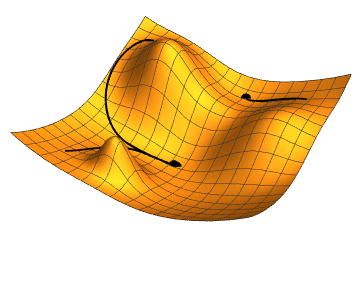
A gradiens-ereszkedés algoritmus a hibrid ajánlómodellek paraméteroptimalizálásának alapja. Forrás: Wikimedia Commons, CC BY-SA 3.0.
Mély tanulás és neurális hibrid modellek
Wide & Deep Learning
A Google 2016-ban tette közzé a Wide & Deep Learning architektúrát (Cheng et al.), amely az alkalmazásáruház ajánlójában debütált. A "wide" komponens egy lineáris modell, amely ritka, keresztezett jellemzőket kezel (memorization). A "deep" komponens egy mélyhálózat, amely sűrű embeddinggekkel dolgozik (generalization). A két rész kimeneteit összevonva egyetlen végső pontszám keletkezik.
Neural Collaborative Filtering (NCF)
Xiangnan He és munkatársai 2017-ben publikálták az NCF keretrendszert, amely a mátrix-faktorizáció nemlineáris általánosítása. Az NCF a felhasználó és elem embeddingjeit neurális hálózaton keresztül kombinálja, lehetővé téve összetettebb interakciós minták modellezését.
// Egyszerűsített NCF architektúra
// Bemenet: felhasználói ID (u), elem ID (i)
// Embedding réteg: e_u = Embedding(u), e_i = Embedding(i)
// Konkatenáció: z = [e_u || e_i]
// Rejtett rétegek: h = ReLU(W_3 · ReLU(W_2 · ReLU(W_1 · z + b_1) + b_2) + b_3)
// Kimenet: ŷ_ui = σ(h^T · h_out) // előre jelzett interakció valószínűsége
Contextual Bandits és megerősítéses tanulás
A modern hibrid rendszerek egyre inkább integrálnak megerősítéses tanulási elemeket (reinforcement learning), különösen a Contextual Bandit megközelítést. Ebben a keretrendszerben az ajánlórendszer ügynökként viselkedik: minden ajánlás egy "akció", amelyre a felhasználó viselkedése (kattintás, vásárlás, görgetés) visszajelzést ad. A cél a kumulatív jutalom maximalizálása hosszabb időhorizonton.
A LinkedIn az álláshirdetési ajánlásaihoz, a Pinterest a pin-ajánlásaihoz is alkalmaz ilyen megközelítéseket, amelyekről nyilvánosan elérhető technikai blogbejegyzéseket tett közzé.
Magyar vonatkozások
Magyarországon az ajánlórendszer-kutatás több fronton is jelen van. A Budapesti Műszaki és Gazdaságtudományi Egyetem (BME) Villamosmérnöki és Informatikai Karán, valamint az ELTE Informatikai Karán folynak releváns kutatások az adaptív rendszerek és a gépi tanulás területén. A hazai e-kereskedelmi szereplők egy részét kiszolgáló ajánlómotor-fejlesztés szintén növekvő igényterületet jelent.
Kiértékelés és online tesztelés
A hibrid modellek összehasonlítása és finomhangolása rendszerint offline A/B-teszteléssel kezdődik szimulált adatokon, majd online A/B-tesztekkel folytatódik valós felhasználókon. Az online tesztek eredményei — különösen a CTR (kattintási arány), a konverziós arány és a felhasználói visszatartás — döntő inputot adnak a rendszer fejlesztési irányaihoz.
„A hibrid megközelítés nem csodaszer: az architektúra komplexitásának növekedése magasabb fenntartási és debugolási költségekkel jár. A döntést mindig az adott üzleti környezet igényei alapján kell meghozni." — RecSys 2023 panel, ACM
Összefoglalás
A hibrid ajánlórendszerek a jelenleg legszélesebb körben alkalmazott architektúrát képviselik, mivel képesek egyszerre kezelni a hidegindítási problémát, az adatritkasságot és a felhasználói kontextus változékonyságát. A mesterséges intelligencia fejlődése — különösen a nagy nyelvi modellek és a transzformer-alapú embedding technikák elterjedése — várhatóan tovább bővíti az ezen a területen alkalmazható eszköztárat.
A cikkben szereplő architektúraleírások általános ismeretterjesztési célokat szolgálnak. A hivatkozott publikációk az ACM Digital Library és az arXiv preprint szerveren nyilvánosan elérhetők. A valós rendszerek implementációi lényegesen összetettebbek és üzletileg érzékeny részleteket tartalmazhatnak.